Reusable Performance Models for Distributed Data Processing
Systems for the processing and analysis of data are nowadays more and more employed in environments of vastly different devices, resources, and levels of reliability. In order to support data analytics pipelines when utilized in such distributed systems, we research solutions for adaptive monitoring, fault tolerance, and related other problems given the aforementioned circumstances. To this end, we are particularly interested in resource efficient and reusable approaches of modeling the performance of individual application and infrastructure aspects.
Motivation
Adaptive monitoring and fault tolerance plays an important role for distributed analytics pipelines. It is here where huge amounts of data are processed, often in changing infrastructure environments and with changing inputs and configurations. Methods solving for particular objectives are thus highly demanded. However, employed methods are often rendered useless if the original context is subject to slight changes. It is therefore necessary to design solutions that are context-aware and thus reusable, while also being as efficient as possible in order to reduce energy consumption and required training time.
Approach
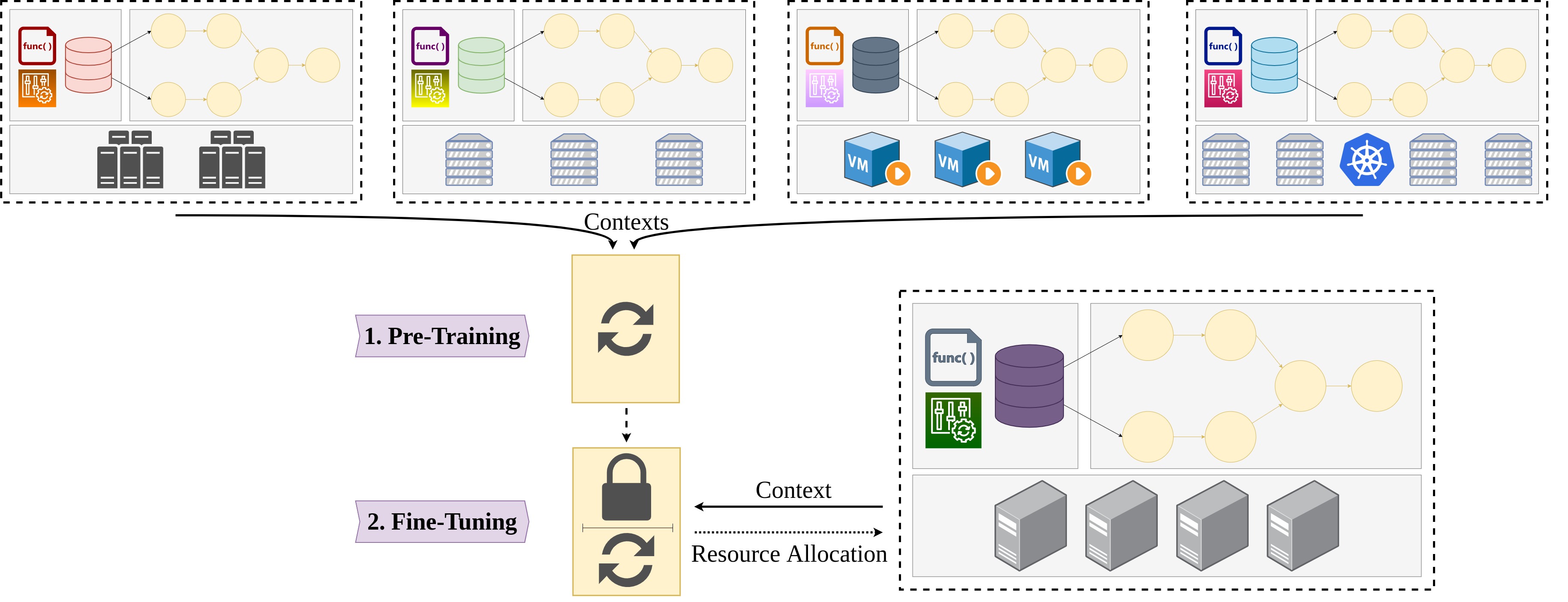
Fig. 1: The main idea behind reusable performance models, here examplary for the problem of resource allocation handled in the Bellamy approach. A model is first learned using data from diverse execution contexts, and eventually optimized for a specific context at hand.
We argue that modeling the target problem and its corresponding context in a generalized fashion still allows for capturing essential information and problem characteristics. Hereby, researching solutions for such transferable models is likely to reduce both costs and time usually required for conducting large-scale data processing. In case of broad context shifts, we argue for combining cross-context knowledge in large and general models, such that a specific problem in a particular context can be efficiently solved by distillation of the general model into specialized and tuned context-specific models.
Results
First attempts of ours show promising results in the domain of runtime prediction for batch processing, which is why we seek to expand and intensify our efforts.
- Bellamy is a novel modeling approach that combines scale-outs, dataset sizes, and runtimes with additional descriptive properties of a dataflow job. It is thereby able to capture the context of a job execution, which allows for incorporating data from different contexts in order to improve the prediction performance.
Publications
- Enel: Context-Aware Dynamic Scaling of Distributed Dataflow Jobs using Graph Propagation. Dominik Scheinert, Houkun Zhu, Lauritz Thamsen, Morgan K. Geldenhuys, Jonathan Will, Alexander Acker, and Odej Kao. To appear in the Proceedings of the 40th IEEE International Performance Computing and Communications Conference (IPCCC). IEEE. 2021. [arXiv preprint]
- Bellamy: Reusing Performance Models for Distributed Dataflow Jobs Across Contexts. Dominik Scheinert, Lauritz Thamsen, Houkun Zhu, Jonathan Will, Alexander Acker, Thorsten Wittkopp, and Odej Kao. In the Proceedings of the 23rd IEEE International Conference on Cluster Computing (CLUSTER). IEEE. 2021. [arXiv preprint]
Contact
If you have any questions or are interested in collaborating with us on this topic, please get in touch with Dominik!
Acknowledgments
This work has been supported through grants by the German Ministry for Education and Research as Berlin Institute for the Foundations of Learning and Data (BIFOLD) (BMBF grant 01IS18025A).