C5: Collaborative and Cross-Context Cluster Configuration for Distributed Data-Parallel Processing
Many organizations routinely analyze large datasets today. For this, they make use of distributed data-parallel processing systems and take advantage of clusters of commodity resources. Especially smaller organizations and individual users are enabled by data processing frameworks and cloud computing, allowing them to work with large datasets at a high-level of abstraction. Still, users are required to configure adequate resources for their data processing jobs. This is often not straightforward and users frequently overprovision resources for their jobs, leading to low resource utilization as well as high costs and energy consumptions.
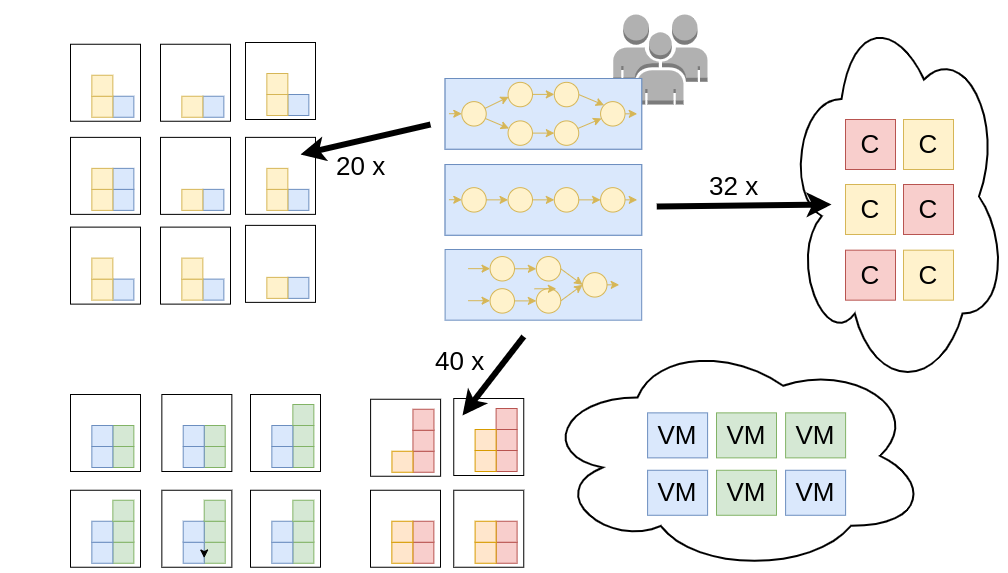
Figure: Users have to determine adequate resource configurations before running their data-parallel distributed processing job on clusters of computer resources.
Numerous works addressed this problem in the last decade for big data frameworks, scientific workflows, and machine learning systems, using statistical tools and performance models. However, much of the effort focused on industry settings, either assuming data on previous executions of jobs to be available or relying on potentially costly dedicated profiling. Little research has addressed use cases where runtime data is not as easily available.
Addressing this research gap, we aim to develop new methods for collaborative use of runtime data. We believe sharing of runtime information across different execution contexts presents a significant opportunity for performance modeling and efficient model-based resource management. This applies to many situations, especially when the availability of runtime data is limited.
Partners
This project is funded by the German Research Foundation ( ![]() ) as project number 506529034.
) as project number 506529034.