Runtime Prediction and Resource Allocation for Distributed Dataflows
Aiming to support distributed dataflow users in meeting their performance expectations with minimal resources, we work on runtime prediction and resource allocation for systems like Spark and Flink.
Motivation
Many organizations need to analyze large datasets such as data collected by thousands of sensors or generated by millions of users.
Even with the parallel capacities that single nodes provide today, the size of some datasets requires the resources of many nodes.
Consequently, distributed systems have been developed to manage and process large datasets with clusters of commodity resources.
A popular class of such distributed systems are distributed dataflow systems like Flink, Spark, and Beam.
These systems offer high-level programming abstractions revolving around frameworks of data-parallel operators, provide efficient and fault-tolerant distributed runtime engines, and come with libraries of common data processing jobs.
These systems thereby make it significantly easier for users to develop scalable data-parallel processing programs that run on large sets of cluster resources.
However, users still need to select adequate resources for their jobs and carefully configure the systems for an efficient distributed processing that meets performance expectations.
Yet, even expert users often do not fully understand system and workload dynamics since many factors determine the runtime behavior of jobs (e.g. programs, input datasets, system implementations and configurations, hardware architectures).
In fact, users currently overprovision heavily to make sure their jobs meet performance expectations, inducing significant overheads and yielding low resource utilizations and, thus, unnecessary costs and energy consumption.
Approach
Instead of having users essentially guess adequate sets of resources and system configurations, resource management systems should support users with these tasks. Yet, to allocate resources for specific distributed dataflow jobs in line with given performance expectations, resource management systems require accurate performance models. Such performance models can be learned either from a cluster’s execution history or dedicated profiling runs (or a combination of both). They allow to predict the runtimes of a job for specific sets of resources. Based on these predictions, a minimal scale-out and set of resources can be chosen automatically in accordance with a user’s runtime target. Furthermore, monitoring of the actual job performance and dynamic adjustments based on performance data and models can be used to address runtime variance.
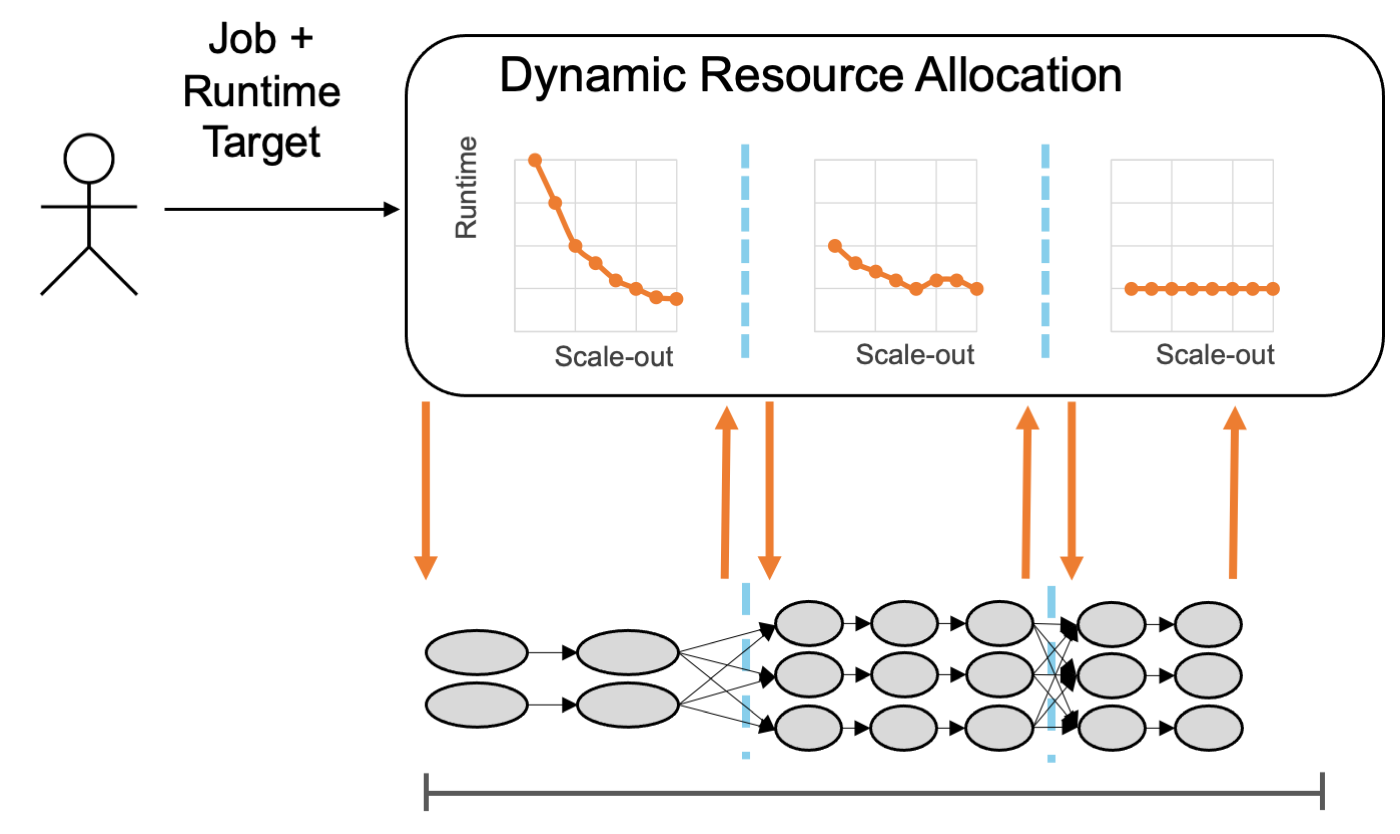
As shown in the figure, the idea is to have a user submit a job with a targeted runtime, but without a specific resource reservation. The specific resource reservation is then calculated using models that estimate the runtime for a specific scale-out. Scale-out models can be trained either for an entire job or for each stage/iteration of a job. In case fine-grained models exist for a job, it is possible to estimate a running job’s progress towards a runtime target, based on the elapsed time and the scale-out models for the remaining stages/iterations, to, if necessary, scale-out a job dynamically. The scale-out models can be trained on previous executions of recurring jobs, selecting similar executions for accurate runtime predictions. Ultimately, this allows users to concentrate on their programs and have systems make more informed resource management decisions.
Results
We developed and evaluated a variety of tools for runtime prediction and resource allocation for distributed dataflows jobs:
- Bell is a system that models the scale-out behavior of distributed dataflow jobs based on previous runs and selects resources according to user-provided runtime targets. It automatically chooses between different regression models to optimally support various systems and situations. It is implemented as a job submission tool for YARN. Learn more in the paper.
- CoBell is a resource allocation method that incorporates information about co-located workloads to improve the runtime prediction for distributed dataflow jobs in shared clusters. It takes into account runtime and scale-out constraints and can be used to reserve resources based on predicted runtimes. Learn more in the paper.
- Cutty is a method for selecting similar previous executions of distributed data-parallel jobs based on their similarity to a currently running job, matching those previous executions that behave similarly and, therefore, allow an accurate performance estimation. For this, Cutty uses several similarity measures, including input size, convergence, and stage runtimes. Learn more in the thesis.
- SMiPE is a system for estimating the progress of iterative dataflows by matching a running job to previous executions based on similarity, capturing characteristic properties such as convergence, resource utilization, and iteration runtime. For this, SMiPE automatically adapts its similarity matching to algorithm-specific profiles, training weights on the job’s history, using the Cutty method. Learn more in the paper.
- Ellis is a resource allocation method for reserving and, if necessary, dynamically adjusting resources for distributed dataflow jobs with runtime targets. Ellis continuously monitors a distributed dataflow job’s progress towards its runtime target using models of the scale-out behavior of individual stages of distributed dataflow jobs. These per-stage scale-out models are trained based on previous execution. Learn more in the paper.
In addition, we also published a dataset that contains 930 unique Spark job executions, along with an analysis of the data that suggests possibilities for a more collaborative approach to performance modeling and cluster configuration optimization.
Publications
- Ruya: Memory-Aware Iterative Optimization of Cluster Configurations for Big Data Processing. Jonathan Will, Jonathan Bader, Dominik Scheinert, Lauritz Thamsen, and Odej Kao. To appear in the Proceedings of the 2022 IEEE International Conference on Big Data (Big Data). IEEE. 2022. [arXiv preprint]
- Get Your Memory Right: The Crispy Resource Allocation Assistant for Large-Scale Data Processing. Jonathan Will, Jonathan Bader, Dominik Scheinert, Lauritz Thamsen, and Odej Kao. To appear in the Proceedings of the 2022 IEEE International Conference on Cloud Engineering (IC2E). IEEE. 2022. [arXiv preprint]
- On the Potential of Execution Traces for Batch Processing Workload Optimization in Public Clouds. Dominik Scheinert, Alireza Alamgiralem, Jonathan Bader, Jonathan Will, Thorsten Wittkopp, Lauritz Thamsen. To appear in the Proceedings of the 2020 IEEE International Conference on Big Data (Big Data). Presented at the 5th International Workshop on Benchmarking, Performance Tuning and Optimization for Big Data Applications (BPOD). IEEE. 2021. [arXiv preprint]
- Enel: Context-Aware Dynamic Scaling of Distributed Dataflow Jobs using Graph Propagation. Dominik Scheinert, Houkun Zhu, Lauritz Thamsen, Morgan K. Geldenhuys, Jonathan Will, Alexander Acker, and Odej Kao. To appear in the Proceedings of the 40th IEEE International Performance Computing and Communications Conference (IPCCC). IEEE. 2021. [arXiv preprint]
- Bellamy: Reusing Performance Models for Distributed Dataflow Jobs Across Contexts. Dominik Scheinert, Lauritz Thamsen, Houkun Zhu, Jonathan Will, Alexander Acker, Thorsten Wittkopp, and Odej Kao. In the Proceedings of the 23rd IEEE International Conference on Cluster Computing (CLUSTER). IEEE. 2021. [arXiv preprint]
- C3O: Collaborative Cluster Configuration Optimization for Distributed Data Processing in Public Clouds. Jonathan Will, Lauritz Thamsen, Dominik Scheinert, Jonathan Bader, and Odej Kao. In the Proceedings of the 9th IEEE International Conference on Cloud Engineering (IC2E). IEEE. 2021. [arXiv preprint] [video]
- Towards Collaborative Optimization of Cluster Configurations for Distributed Dataflow Jobs. Jonathan Will, Jonathan Bader, and Lauritz Thamsen. In the Proceedings of the 2020 IEEE International Conference on Big Data (Big Data). Presented at the 4th International Workshop on Benchmarking, Performance Tuning and Optimization for Big Data Applications (BPOD). IEEE. 2020. [arXiv preprint] [video] [data]
- CoBell: Runtime Prediction for Distributed Dataflow Jobs in Shared Clusters. Ilya Verbitskiy, Lauritz Thamsen, Thomas Renner, and Odej Kao. In the Proceedings of the 10th IEEE International Conference on Cloud Computing Technology and Science (CloudCom). IEEE. 2018. [Google Scholar]
- Ellis: Dynamically Scaling Distributed Dataflows to Meet Runtime Targets. Lauritz Thamsen, Ilya Verbitskiy, Jossekin Beilharz, Thomas Renner, Andreas Polze, and Odej Kao. In the Proceedings of the 9th IEEE International Conference on Cloud Computing Technology and Science (CloudCom). IEEE. 2017. [Google Scholar] [code]
- SMiPE: Estimating the Progress of Recurring Iterative Distributed Dataflows. Jannis Koch, Lauritz Thamsen, Florian Schmidt, and Odej Kao. In the Proceedings of the 18th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT). IEEE. 2017. [Google Scholar] [code]
- Selecting Resources for Distributed Dataflow Systems According to Runtime Targets. Lauritz Thamsen, Ilya Verbitskiy, Florian Schmidt, Thomas Renner, and Odej Kao. In the Proceedings of the 35th IEEE International Performance Computing and Communications Conference (IPCCC). IEEE. 2016. [Google Scholar] [code] [data]
Contact
If you have any questions or are interested in collaborating with us on this topic, please get in touch with Lauritz!
Acknowledgments
This work has been supported through grants by the German Science Foundation as Stratosphere (DFG Research Unit FOR 1306) and FONDA (DFG Collaborative Research Center 1404) as well as by the German Ministry for Education and Research as Berlin Big Data Center BBDC (BMBMF grant 01IS14013A) and Berlin Institute for the Foundations of Learning and Data BIFOLD (BMBF grant 01IS18025A).