Collaborative Resource Optimization for Distributed Data Processing
We currently do research on optimizing resource configurations for distributed data-parallel processing. One of our focuses here is supporting sporadic data processing needs by users who only infrequently need to process large amounts of data. This setting implies that there is no private cluster of bare-metal machines, instead public clouds are used. Also, neither experienced data engineers, nor extensive runtime metrics from previous executions can help the users to choose good configurations.
Motivation
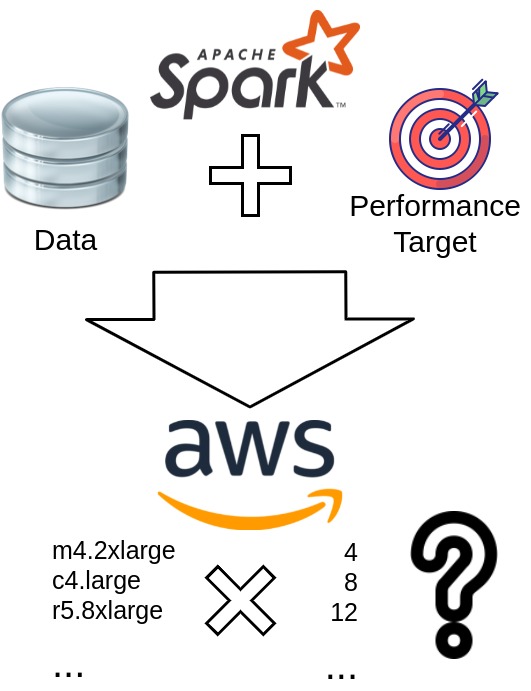
Distributed dataflow systems like Apache Spark and Flink simplify developing scalable data-parallel programs, reducing especially the need to implement parallelism and fault tolerance.
However, it is often not straightforward to select resources and configure clusters for efficiently executing such programs.
This is the case especially for users who only infrequently run large-scale data processing jobs and without the help of systems operations staff.
For instance, today, many organizations have to analyze large amounts of data every now and then. Examples are small to medium-sized companies, public sector organizations, and scientists.
Common application areas are bioinformatics, geosciences, or physics.
The sporadic nature of many data processing use cases makes using public clouds substantially cheaper when compared directly to investing in private cloud/cluster setups.
In cloud environments, especially public clouds, there are several virtual machine types with different hardware configurations available.
Therefore, users can select the most suitable machine type according to their needs.
In addition, they can choose the horizontal scale-out, avoiding potential bottlenecks and significant over-provisioning for their workload.
Most users will also have expectations for the runtime of their jobs.
However, estimating the performance of a distributed data-parallel job is difficult, and users typically overprovision resources to meet their performance targets.
Yet this happens often at the cost of overheads, which increase with larger scale-outs.
Approach
We work on systems with runtime prediction models for collaborative cluster
configuration optimization based on shared runtime data.
Since many different users and organizations use the same public
cloud resources, they could also collaborate in performance modeling and selecting good cluster configurations.
We expect especially researchers to be willing to share not just jobs, but also runtime metrics on the execution of jobs, in principle already providing a basis for performance modeling.
Results
We conceptionalized the following approaches and systems:
- We propose a collaborative approach for finding optimal cluster configurations based on sharing and learning from historical runtime data of distributed dataflow jobs. Collaboratively shared data can be utilized to predict runtimes of future job executions through the use of specialized regression models. However, training prediction models on historical runtime data that were produced by different users and in diverse contexts requires the models to take these contexts into account. Learn more in the paper.
- More to follow…
Publications
- Training Data Reduction for Performance Models of Data Analytics Jobs in the Cloud. Jonathan Will , Onur Arslan , Jonathan Bader , Dominik Scheinert , and Lauritz Thamsen. To appear in the Proceedings of the 2020 IEEE International Conference on Big Data (Big Data). Presented at the 5th International Workshop on Benchmarking, Performance Tuning and Optimization for Big Data Applications (BPOD). IEEE. 2021. [arXiv preprint] [video]
- C3O: Collaborative Cluster Configuration Optimization for Distributed Data Processing in Public Clouds. Jonathan Will, Lauritz Thamsen, Dominik Scheinert, Jonathan Bader, and Odej Kao. In the Proceedings of the 9th IEEE International Conference on Cloud Engineering (IC2E). IEEE. 2021. [arXiv preprint] [video]
- Towards Collaborative Optimization of Cluster Configurations for Distributed Dataflow Jobs. Jonathan Will, Jonathan Bader, and Lauritz Thamsen. In the Proceedings of the 2020 IEEE International Conference on Big Data (Big Data). Presented at the 4th International Workshop on Benchmarking, Performance Tuning and Optimization for Big Data Applications (BPOD). IEEE. 2020. [arXiv preprint] [video] [data]
Contact
If you have any questions or are interested in collaborating with us on this topic, please get in touch with Jonathan Will!
Acknowledgments
This work has been supported through grants by the German Science Foundation as FONDA (DFG Collaborative Research Center 1404) as well as by the German Ministry for Education and Research as Berlin Institute for the Foundations of Learning and Data BIFOLD (BMBF grant 01IS18025A).