Co-Locating Distributed Data-Parallel Jobs in Shared Clusters
Cluster resource utilization and makespan can often be significantly improved when data-parallel batch processing jobs share cluster resources without much isolation. However, how much workloads benefit from resource sharing depends on the specific job combinations that run together, so co-locations should be selected taking resource utilizations and interferences into account.
Motivation
Distributed data-parallel batch processing systems like MapReduce, Spark, and Flink are popular tools for analyzing large datasets using cluster resources. Resource management systems like YARN or Mesos in turn allow multiple data-parallel processing jobs to share cluster resources using temporary container reservations. Often, the containers do not isolate resource usage to achieve high degrees of overall resource utilization, despite overprovisioning and the typically fluctuating resource demands of long-running batch processing jobs. That is, it is often beneficial for resource utilization and makespan to co-locate jobs that stress different resources. However, some combinations of jobs utilize resources significantly better and interfere less with each other when running on the same shared nodes, compared to others. This is, however, often not clear without actually running specific jobs together with other jobs in a particular cluster environment.
Approach
Recurring data processing jobs provide an opportunity to monitor and learn how specific jobs and job combinations utilize shared cluster resources. This knowledge can inform scheduling decisions. More specifically, our approach to scheduling recurring distributed dataflow jobs employs reinforcement learning to select jobs that stress different resources than the jobs already running on a cluster.
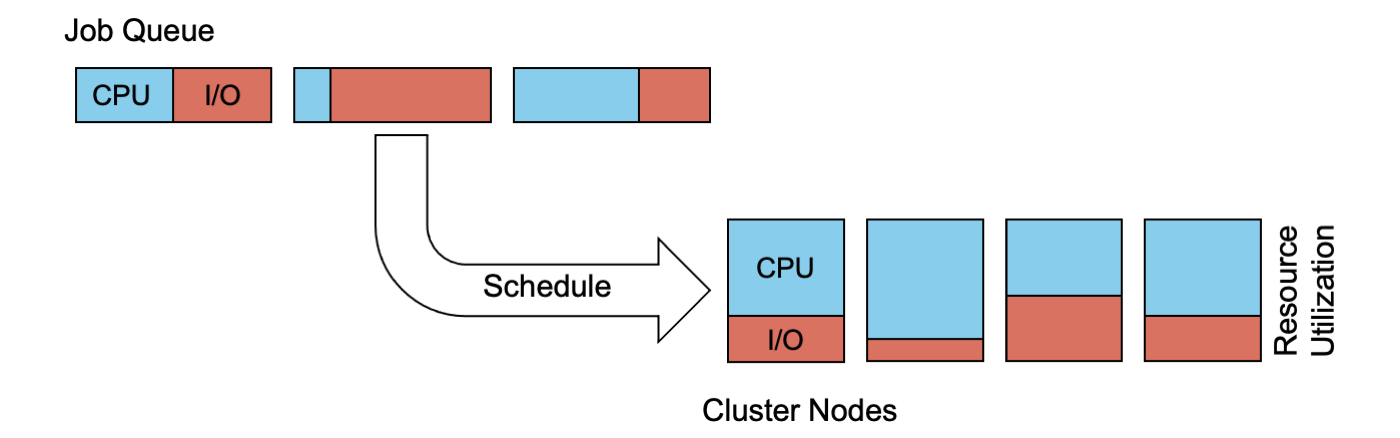
Our approach takes the resource utilization of and interference among co-located jobs into account. Furthermore, we continuously learn which combinations of jobs should be promoted or prevented, when it comes to co-locating them on shared nodes. Thereby, changes in the behavior of recurring jobs due to, for instance, modified input data or changed job parameters, will also be automatically reflected in our scheduler’s model of co-location goodness over time.
Results
We developed and evaluated a family of cluster schedulers that co-locate data-parallel batch processing jobs on sahred cluster resources using reinforcement learning, aiming to optimize makespan by selecting combinations that exhibit a high resource utilization and low interference: The first scheduler, which we call Mary, implements the reinforcement learning algorithm and measure of co-location goodness. The second scheduler, which we call Hugo, builds on the first scheduler and adds offline grouping of jobs to provide a scheduling mechanism that efficiently generalizes from already monitored job combinations. The third scheduler, which we call Hugo*, adds bounded waiting, showing how additional scheduling requirements can be integrated. We implemented all our scheduler variants for YARN and used exemplary Flink and Spark jobs to demonstrate the impact on cluster resource utilization, makespan, and waiting times.
Publications
- Mary, Hugo, and Hugo*: Learning to Schedule Distributed Data-Parallel Processing Jobs on Shared Clusters. Lauritz Thamsen, Jossekin Beilharz, Vinh Thuy Tran, Sasho Nedelkoski, and Odej Kao. In Concurrency and Computation: Practice and Experience (e5823). Wiley. 2020. [Open Access] [code]
- Hugo: A Cluster Scheduler that Efficiently Learns to Select Complementary Data-Parallel Jobs. Lauritz Thamsen, Ilya Verbitskiy, Sasho Nedelkoski, Vinh Thuy Tran, Vinícius Meyer, Miguel G. Xavier, Odej Kao, and César A. F. De Rose. In the Proceedings of the Euro-Par 2019 Workshops (Euro-Par). Presented at the 1st International Workshop on Parallel Programming Models in High-Performance Cloud. Springer. 2019. [Google Scholar] [code]
- Learning Efficient Co-locations for Scheduling Distributed Dataflows in Shared Clusters. Lauritz Thamsen, Ilya Verbitskiy, Benjamin Rabier, and Odej Kao. In Services Transactions on Big Data (Vol. 4, No. 1). Services Society. 2018. [Open Access]
- Scheduling Recurring Distributed Dataflow Jobs Based on Resource Utilization and Interference. Lauritz Thamsen, Benjamin Rabier, Florian Schmidt, Thomas Renner, and Odej Kao. In the Proceedings of the 6th IEEE BigData Congress. IEEE. 2017. [Google Scholar] [code]
Contact
If you have any questions or are interested in collaborating with us on this topic, please get in touch with Lauritz!
Acknowledgments
This work has been supported through grants by the German Science Foundation as Stratosphere (DFG Research Unit FOR 1306) as well as by the German Ministry for Education and Research as Berlin Big Data Center BBDC (BMBMF grant 01IS14013A) and Berlin Institute for the Foundations of Learning and Data BIFOLD (BMBF grant 01IS18025A).